Claude 3係Anthropic開發嘅最新大型語言模型,佢喺多方面展示出嚟對OpenAI GPT-4模型嘅優勢。首先,喺遵循用戶指令同處理視覺任務方面,Claude 3喺特定基準測試中表現出色。例如,當要求生成以特定單詞結尾嘅句子時,Claude 3能夠準確地生成符合要求嘅句子,而GPT-4就表現稍遜一點。
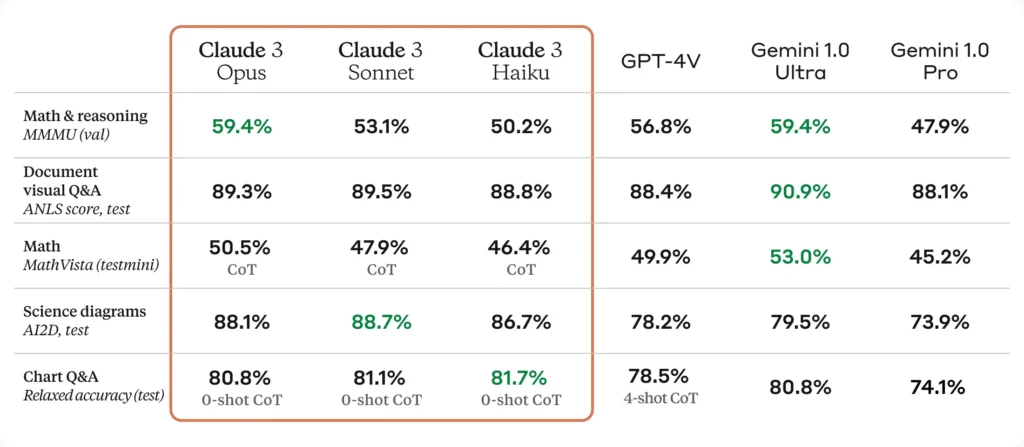
喺視覺能力方面,Claude 3展示咗佢強大嘅圖像分析能力,能夠正確識別同解釋圖像內容。特別係處理含有圖像嘅問題時,Claude 3同GPT-4都能夠給出正確嘅電影名,顯示Claude 3喺圖像處理方面同GPT-4處於同等水平。
此外,Claude 3喺數學問題解決方面都表現出色,佢喺MATH基準測試中嘅得分超過咗GPT-4,顯示出佢喺此類問題上嘅強大能力。Claude 3仲喺處理非英語語言嘅能力上有所提升,使佢成為一個更加多元化同全球化嘅語言模型。
總結嚟講,Claude 3憑住佢喺遵循用戶指令、圖像處理同數學問題解決方面嘅強大性能,以及對非英語語言嘅支持,展示咗對GPT-4模型嘅優勢。呢啲特點使Claude 3成為喺特定領域表現更佳嘅選擇,尤其係對於啲需要處理複雜視覺內容或特定語言嘅用戶嚟講。不過,揀邊個模型最終仲係要根據具體嘅應用需求同偏好決定 (主要係使用CLAUDE 3 比GPT 4 成本還要貴得多 TT)。
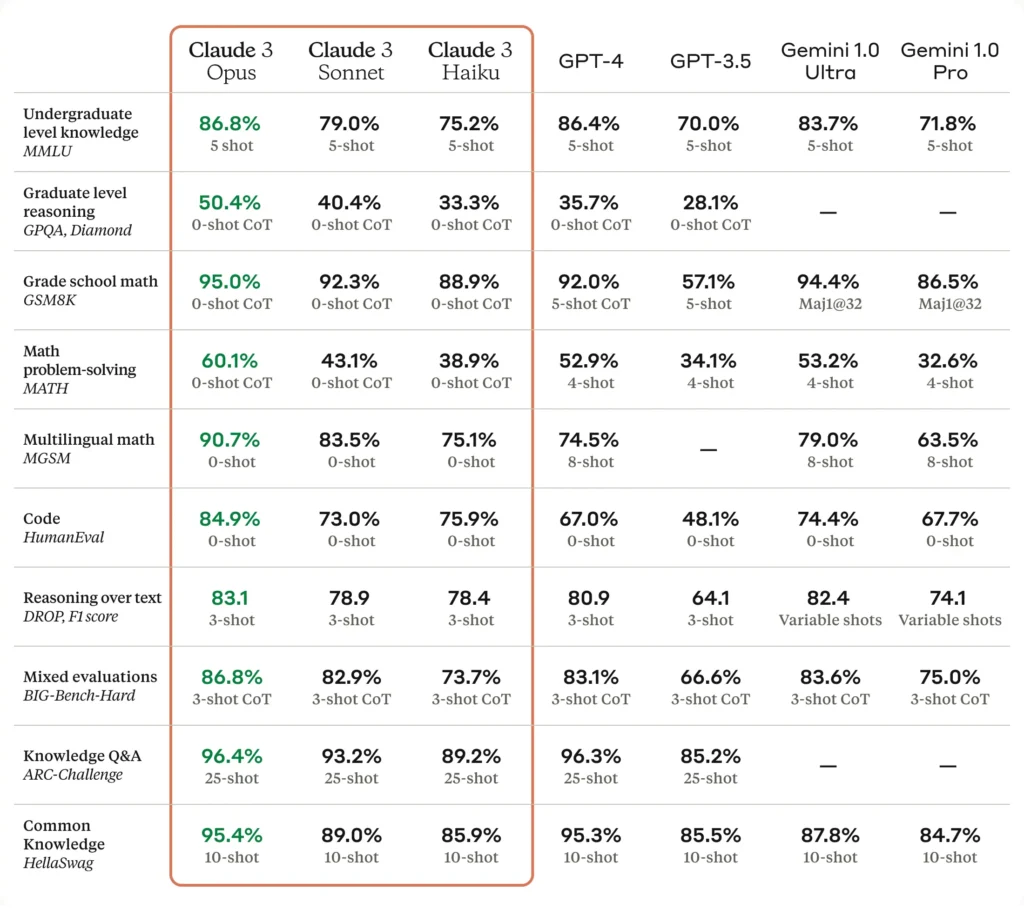
喺細節更多嘅技術測試,例如編程能力(Code HumanEval),Opus都表現得好好,拎到84.9%,高過GPT-4嘅67%。喺數學問題解決(Math Problem-solving MATH)測試上,Opus同樣領先,有60.1%嘅成績,而GPT-4就有52.9%。喺多語言數學(Multilingual math MGSM)嘅測試中,Opus拎到90.7%嘅成績,明顯高過GPT-4嘅74.5%。呢個顯示咗Opus喺處理數學問題上嘅優勢。